Gradient-based optimization
After reviewing some of the basic concepts of linear algebra and probability that we will be using during this course, we are now in a position to start our journey in the field of learning algorithms.
Any learning algorithm, no matter its level of complexity, is composed of 4 key elements:
Dataset: a collection of many examples (sometimes referred to as samples of data points) that represents the experience we wish our machine learning algorithm to learn from. More specifically, the dataset is defined as:
and
where and are the number of features and targets for each sample in the dataset, respectively, and is the number of samples.
Model: a mathematical relation between the input (or features) and output (or target) of our dataset. It is generally parametrized as function of a number of free parameters which we want the learning algorithm to estimate given a task and a measure of performance, and we write it as
Loss (and cost) function: quantitative measure of the performance of the learning algorithm, which we wish to minimize (or maximize) in order to make accurate predictions on the unseen data. It is written as
where is the loss function for each input-output pair and is the overall cost function.
Optimization algorithm: mathematical method that aims to drive down (up) the cost function by modifying its free-parameters :
Optimization algorithms are generally divided into two main families: gradient-based (or local) and gradient-free (or global). Gradient-based optimization is by far the most popular way to train NNs and will be discussed in more details below.
Gradient-descent algorithms¶
The simplest of gradient-based methods is the so-called Gradient-descent algorithms (e.g., steepest descent algorithm). As the name implies, this algorithm uses local gradient information of the functional to minimize/maximize to move towards its global mimimum/maximum as depicted in the figure below.

More formally, given a functional and its gradient , the (minimization) algorithm can be written as:
Initialization: choose
For ;
- Compute update direction
- Estimate step-lenght
- Update
Note that the maximization version of this algorithm simply swaps the sign in the update direction (first equation of the algorithm). Moreover, the proposed algorithm can be easily extended to N-dimensional model vectors by defining the following gradient vector .
Step length selection¶
The choice of the step-length has tremendous impact on the performance of the algorithm and its ability to converge fast (i.e., in a small number of iterations) to the optimal solution.
The most used selection rules are:
- Constant: the step size is fixed to a constant value . This is the most common situation that we will encounter when training neural networks. In practice, some adaptive schemes based on the evolution of the train (or validation) norm are generally adopted, but we will still refer to this case as constant step size;
- Exact line search: at each iteration, is chosen such that it minimizes . This is the most commonly used approach when dealing with linear systems of equations.
- Backtracking "Armijo" line search: at each iteration, given a parameter , start with and reduce it by a factor of 2 until the following condition is satisfied:
Second-order optimization¶
Up until now we have discussed first-order optimization techniques that rely on the ability to evaluate the function and its gradient . Second-order optimization method go one step beyond in that they use information from both the local slope and curvature of the function .
When a function has small curvature, the function and its tangent line are very similar: the gradient alone is therefore able to provide a good local approximation of the function (i.e., ). On the other hand, if the curvature of the function of large, the function and its tangent line start to differ very quickly away from the linearization point. The gradient alone is not able anymore to provide a good local approximation of the function (i.e., ).
Let's start again from the one-dimensional case and the well-known Newton's method. This method is generally employed to find the zeros of a function: and can be written as:
which can be easily derived from the Taylor expansion of around .
If we remember that finding the minimum (or maximum) of a function is equivalent to find the zeros of its first derivative (), the Newton's method can be written as:
In order to be able to discuss second-order optimization algorithms for the multi-dimensional case, let's first introduce the notion of Jacobian:
Through the notion of Jacobian, we can define the Hessian as the Jacobian of the gradient vector
where we note that when is continuous, , and is symmetric.
The Newton method for the multi-dimensional case becomes:
Approximated version of the Newton method have been developed over the years, mostly based on the idea that inverting is sometimes a prohibitive task. Such methods, generally referred to as Quasi-Netwon methods attempt to approximate the Hessian (or its inverse) using the collections of gradient information from the previous iterations. BFGS or its limited memory version L-BFGS are examples of such a kind. Due to their computational cost (as well as the lack of solid theories for their use in conjunction with approximate gradients), these methods are not yet commonly used by the machine learning community to optimize the parameters of NNs in deep learning.
Stochastic-gradient descent (SGD)¶
To conclude, we look again at gradient-based iterative solvers and more specifically in the context of finite-sum functionals of the kind that we will encountering when training neural networks:
where the summation here is performed over training data.
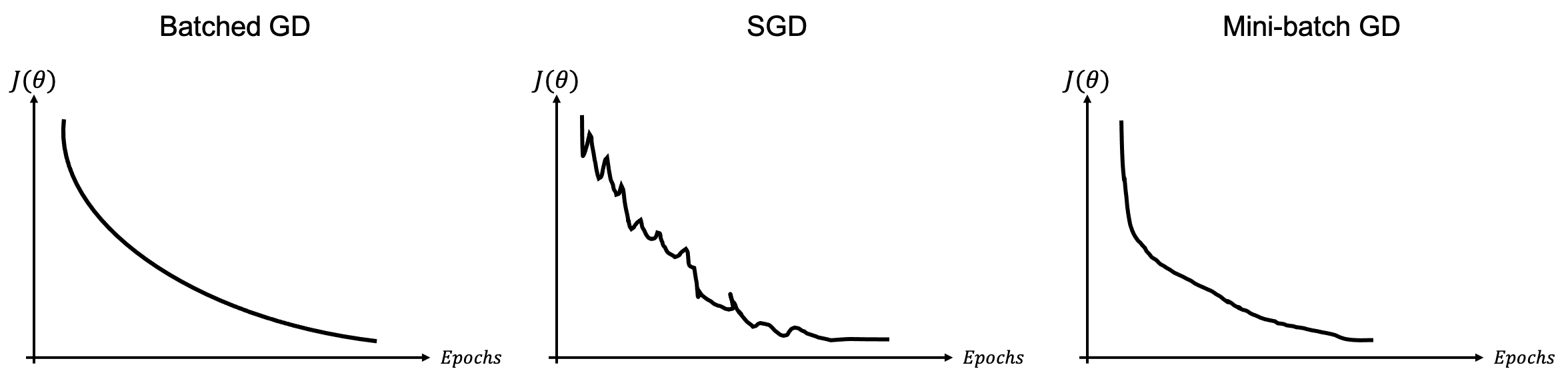
Batched gradient descent¶
The solvers that we have considered so far are generally update the model parameters using the full gradient (i.e., over the entire batch of samples):
A limitation of such an approach is that, if we have a very large number of training samples, the computational cost of computing the full gradient is very high and when some of the samples are similar, their gradient contribution is somehow redundant.
Stochastic gradient descent¶
In this case we take a completely opposite approach to computing the gradient. More specifically, a single training sample is considered at each iteration:
The choice of the training sample at each iteration is generally completely random and this is repeated once all training data have been used at least once (generally referred to as epoch). In this case, the gradient may be noisy because the gradient of a single sample is a very rough approximation of the total cost function : such a high variance of gradients requires lowering the step-size leading to slow convergence.
Mini-batched gradient descent¶
A more commonly used strategy lies in between the batched and stochastic gradient descent algorithms uses batches of training samples to compute the gradient at each iteration. More specifically given a batch of samples, the update formula can be written as:
and similarly to the stochastic gradient descent, the batches of data are chosen at random and this is repeated as soon as all data are used once in the training loop. Whilst the choice of the size of the batch depends on many factors (e.g., overall size of the dataset, variety of training samples), common batch sizes in training of NNs are from around 50 to 256 (unless memory requirements kick in leading to even small batch sizes).
Additional readings¶
- the following blog post for a more detailed overview of the optimization algorithms discussed here. Note that in one of our future lectures we will also look again at the optimization algorithms and more specifically discuss strategies that allow overcoming some of the limitations of standard SGD in this lecture.